

Robots.txt je datoteka koja služi da upravlja ponašanjem pretraživačkih robota (crawler-a) na vašem veb sajtu. Ovaj vodič će vam pružiti sveobuhvatan pregled kako da pravilno koristite robots.txt fajl za poboljšanje SEO (optimizacije za pretraživače) performansi vašeg sajta.
Šta je robots.txt?
Robots.txt je tekstualna datoteka smeštena na vašem veb serveru koja komunicira sa pretraživačkim robotima i drugim web crawler-ima, navodeći ih koje delove vašeg sajta smeju ili ne smeju da posete. Ova datoteka vam omogućava da kontrolišete koje stranice želite da budu indeksirane (crawlable) i koje ne želite.
Zašto je robots.txt važan za SEO?
Pravilno konfigurisan robots.txt fajl je važan za SEO iz nekoliko razloga:
- Poboljšava efikasnost crawlovanja: Pretraživački roboti koriste robots.txt kako bi saznali koje stranice smeju da posete. Ovaj fajl vam omogućava da usmerite crawlere na najvažnije delove vašeg sajta, što poboljšava efikasnost crawl procesa.
- Kontroliše indeksiranje: Pomoću robots.txt možete blokirati pristup određenim delovima vašeg sajta, poput administrativnih panela ili privremenih stranica. To osigurava da pretraživači ne indeksiraju ili prikazuju sadržaj koji ne želite da bude vidljiv na rezultatima pretrage.
- Smanjuje opterećenje servera: Blokirajući pristup nepotrebnim delovima sajta, možete smanjiti opterećenje na vašem serveru, čime se poboljšava brzina učitavanja i performanse sajta.
Kako pravilno konfigurisati robots.txt?
Evo nekoliko ključnih smernica za pravilno konfigurisanje robots.txt fajla:
- Pažljivo proverite robots.txt: Pre nego što ga postavite na veb server, pažljivo proverite sadržaj vašeg robots.txt fajla kako biste izbegli greške koje mogu dovesti do blokiranja važnih delova sajta.
- Komentari u robots.txt: Možete koristiti komentare (#) u robots.txt fajlu kako biste opisali svrhu određenih pravila i olakšali razumevanje drugima koji pregledaju fajl.
- Navedite User-agent: U robots.txt fajlu, svako pravilo treba da bude navedeno uz User-agent koji se odnosi na određenog pretraživačkog robota.
- Upotreba Disallow: Disallow direktiva se koristi da blokira pretraživačke robote da pristupaju određenim stranicama ili direktorijumima na vašem sajtu. Na primer, “Disallow: /privatno/” će sprečiti crawlere da posete sve stranice unutar /privatno/ direktorijuma.
- Upotreba Allow: Allow direktiva vam omogućava da eksplicitno dozvolite pretraživačkim robotima pristup određenim stranicama ili direktorijumima, čak i ako postoji opšta Disallow direktiva koja ih blokira.
- Sitemap referenca: U robots.txt fajlu možete takođe dodati referencu na vaš XML Sitemap kako biste pretraživačkim robotima olakšali pronalaženje i indeksiranje vašeg sadržaja.
Proverite ispravnost robots.txt fajla
Pre nego što postavite robots.txt na vaš veb server, koristite alate za testiranje robots.txt kako biste proverili da li je ispravno konfigurisan. Google Search Console takođe pruža alate za proveru ispravnosti vašeg robots.txt fajla i upozorava vas na eventualne greške.
Ukratko, robots.txt je moćan alat za SEO koji vam omogućava kontrolu nad crawl procesom pretraživačkih robota. Pravilno konfigurisan robots.txt fajl može poboljšati indeksiranje i vidljivost vašeg sajta na rezultatima pretrage, poboljšati performanse i smanjiti opterećenje na serveru. Stoga pažljivo planirajte i proverite vaš robots.txt kako biste postigli najbolje rezultate za vaš sajt i optimizaciju za pretraživače.
Terminologija u vezi sa robots.txt fajlom
Robots.txt fajl predstavlja implementaciju standarda za isključenje robota, takođe poznatog kao protokol za isključenje robota.
Zašto je važno brinuti o robots.txt-u?
Robots.txt igra ključnu ulogu sa SEO aspekta. On obaveštava pretraživače kako najbolje mogu obići vaš veb sajt.
Korišćenjem robots.txt fajla, možete sprečiti pretraživače da pristupe određenim delovima vašeg sajta, sprečiti dupliranje sadržaja i pružiti pretraživačima korisne savete kako mogu efikasnije obići vaš sajt.
Ipak, budite pažljivi prilikom izmena robots.txt fajla: ovaj fajl ima potencijal da učini velike delove vašeg sajta nedostupnim za pretraživače.
“Robots.txt is often over used to reduce duplicate content, thereby killing internal linking so be really careful with it. My advice is to only ever use it for files or pages that search engines should never see, or can significantly impact crawling by being allowed into. Common examples: log-in areas that generate many different urls, test areas or where multiple facetted navigation can exist. And make sure to monitor your robots.txt file for any issues or changes.“
Gerry White, SEO
Hajde da pogledamo primer kako bi ovo ilustrovali:
Vodite eCommerce veb sajt gde posetioci mogu koristiti filter da brzo pretraže vaše proizvode. Ovaj filter generiše stranice koje praktično prikazuju isti sadržaj kao i druge stranice. To odlično funkcioniše za korisnike, ali zbunjuje pretraživače jer stvara duplicirani sadržaj.
Ne želite da pretraživači indeksiraju ove filtrirane stranice i gube svoje dragoceno vreme na URL-ove sa filtriranim sadržajem. Zbog toga biste trebali postaviti pravila Disallow kako pretraživači ne bi pristupali ovim filtriranim stranicama sa proizvodima.
Prevenciju dupliciranog sadržaja takođe možete postići korišćenjem kanoničkog URL-a ili meta robots oznake, međutim, ovo ne rešava pitanje omogućavanja pretraživačima da pretražuju samo stranice koje su bitne.
Korišćenje kanoničkog URL-a ili meta robots oznake neće sprečiti pretraživače da pretražuju ove stranice. Samo će sprečiti pretraživače da prikažu ove stranice u rezultatima pretrage. Pošto pretraživači imaju ograničeno vreme za pretraživanje veb sajta, to vreme treba koristiti na stranicama koje želite da se pojave u rezultatima pretrage.
“The mass majority of issues I see with robots.txt files fall into three buckets:
Paul Shapiro, Head of Technical SEO & SEO Product Management, Shopify
- The mishandling of wildcards. It’s fairly common to see parts of the site blocked off that were intended to be blocked off. Sometimes, if you aren’t careful, directives can also conflict with one another.
- Someone, such as a developer, has made a change out of the blue (often when pushing new code) and has inadvertently altered the robots.txt without your knowledge.
- The inclusion of directives that don’t belong in a robots.txt file. Robots.txt is web standard, and is somewhat limited. I oftentimes see developers making directives up that simply won’t work (at least for the mass majority of crawlers). Sometimes that’s harmless, sometimes not so much.”
Kako izgleda robots.txt fajl?
Evo primera jednostavnog robots.txt fajla za WordPress veb sajt:
User-agent: *
Disallow: /wp-admin/Hajde da objasnimo strukturu robots.txt fajla na osnovu gorenavedenog primera:
User-agent: user-agent označava za koje pretraživače su namenjene direktive koje slede.
*: ovo označava da su direktive namenjene svim pretraživačima.
Disallow: ovo je direktiva koja označava koji sadržaj nije dostupan za user-agent.
/wp-admin/: ovo je putanja koja nije dostupna za user-agent.
Ukratko: ovaj robots.txt fajl govori svim pretraživačima da ne pristupaju direktorijumu /wp-admin/.
Hajde da detaljnije analiziramo različite komponente robots.txt fajlova:
- User-agent
- Disallow
- Allow
- Sitemap
- Crawl-delay
User-agent u robots.txt fajlu
Svaki pretraživač treba da se identifikuje sa user-agentom. Na primer, Google-ovi roboti se identifikuju kao Googlebot, Yahoo-ovi roboti kao Slurp, Bing-ovi roboti kao BingBot i tako dalje.
Zapis user-agenta definiše početak grupe direktiva. Sve direktive između prvog user-agenta i sledećeg zapisa user-agenta se tretiraju kao direktive za prvi user-agent.
Direktive se mogu primeniti na određene user-agente, ali mogu važiti i za sve user-agente. U tom slučaju se koristi specijalni simbol: User-agent: *.
Disallow direktiva u robots.txt fajlu
Možete pretraživačima reći da ne pristupaju određenim fajlovima, stranicama ili sekcijama vašeg veb sajta. To se postiže korišćenjem Disallow direktive. Disallow direktiva je praćena putanjom koja ne sme biti pristupljena. Ako putanja nije definisana, direktiva se ignoriše.
Primer

U primeru iznad, svim pretraživačima je zabranjen pristup direktorijumu /media/, osim za fajl /media/terms-and-conditions.pdf.
Važno: kada koristite Allow i Disallow direktive zajedno, obratite pažnju da ne koristite specijalne simbole (*) jer to može dovesti do konfliktnih direktiva.
Evo primera sukobljenih direktiva u robots.txt fajlu
User-agent: *
Disallow: /private/User-agent: Googlebot
Allow: /private/U ovom primeru postoje dva zapisa za user-agente. Prvi je za sve pretraživače (User-agent: *), i zabranjuje pristup direktorijumu /private/. Drugi zapis je specifičan za Googlebot i dozvoljava pristup istom direktorijumu /private/.
Ovo stvara konflikt jer su direktive kontradiktorne. Prva direktiva govori svim pretraživačima da ne pristupaju /private/, dok druga direktiva govori Googlebot-u da može pristupiti /private/. U ovom slučaju, pretraživač možda neće znati šta da radi i potencijalno će ignorisati sukobljene direktive. Kao rezultat, stvarno ponašanje pretraživača prema direktorijumu /private/ može biti nepredvidivo. Da biste izbegli sukobljene direktive, važno je da budu jasne i dosledne za sve user-agente.

Pretraživači neće znati šta da rade sa URL-om http://www.domain.com/directory.html. Nije im jasno da li im je dozvoljen pristup. Kada direktive nisu jasne Google-u, oni će se odlučiti za najmanje restriktivnu direktivu, što u ovom slučaju znači da će zaista pristupiti http://www.domain.com/directory.html.
Dodavanje XML sitemap-a u robots.txt
Iako je robots.txt fajl prvobitno osmišljen da pretraživačima kaže koje stranice ne smeju da pretražuju, robots.txt fajl takođe može biti korišćen da usmeri pretraživače na XML sitemap. Ovo je podržano od strane Google-a, Bing-a, Yahoo-a i Ask-a.
XML sitemap treba biti referisan kao apsolutni URL. URL ne mora biti na istom serveru kao i robots.txt fajl.
Referenciranje XML sitemap-a u robots.txt fajlu je jedna od najboljih praksi koju vam savetujemo da uvek primenjujete, čak i ako ste već poslali vaš XML sitemap putem Google Search Console-a ili Bing Webmaster Tools-a. Zapamtite, postoji mnogo drugih pretraživača.
Napomena: moguće je referencirati više XML sitemap-a u robots.txt fajlu.
User-agent: * Disallow: /wp-admin/
Sitemap: https://www.example.com/sitemap1.xml
Sitemap: https://www.example.com/sitemap2.xmlPrimer iznad govori svim pretraživačima da ne pristupaju direktorijumu /wp-admin/ i da postoje dva XML sitemap-a koji se mogu naći na adresama https://www.example.com/sitemap1.xml i https://www.example.com/sitemap2.xml.
Jedan XML sitemap definisan u robots.txt fajlu:
User-agent: * Disallow: /wp-admin/
Sitemap: https://www.example.com/sitemap_index.xmlPrimer iznad govori svim pretraživačima da ne pristupaju direktorijumu /wp-admin/ i da se XML sitemap može naći na adresi https://www.example.com/sitemap_index.xml.
Crawl kašnjenje u robots.txt fajlu
Crawl-delay direktiva je nezvanična direktiva koja se koristi da se spreči preopterećenje servera previše zahteva. Ako pretraživači mogu preopteretiti server, dodavanje Crawl-delay u vaš robots.txt fajl je samo privremeno rešenje. Suština je da vaš veb sajt radi na lošem hosting okruženju i/ili vaš veb sajt je netačno konfigurisan, i to biste trebali što pre popraviti.
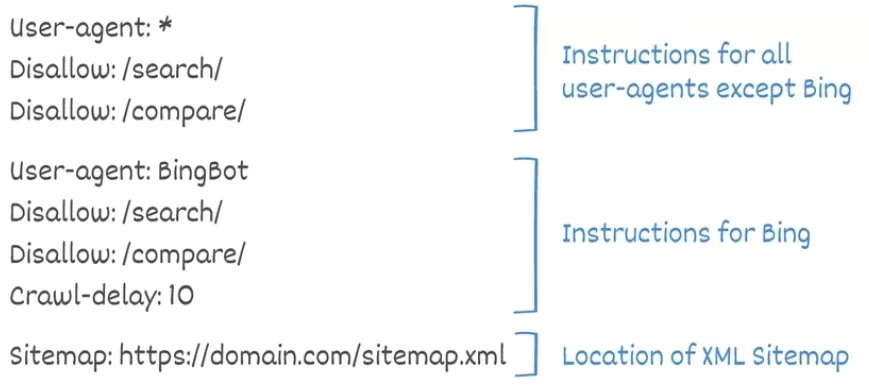
Robots.txt najbolje izdvojeno
Lokacija i ime fajla
Robots.txt fajl uvek treba da se nalazi u korenom direktorijumu veb sajta (u najvišem nivou direktorijuma na serveru) i nosi ime robots.txt, na primer: https://www.example.com/robots.txt. Imajte na umu da je URL za robots.txt fajl, kao i svaki drugi URL, osetljiv na veličinu slova.
Ako robots.txt fajl nije pronađen na podrazumevanoj lokaciji, pretraživači će pretpostaviti da nema direktiva i pretraživaće vaš veb sajt.
Redosled prethodnosti
Važno je napomenuti da pretraživači obrađuju robots.txt fajlove na različite načine. Prema podrazumevanju, uvek pobeđuje prva podudarna direktiva.
Međutim, kod Google-a i Bing-a, specifičnost pobeđuje. Na primer: Allow direktiva pobeđuje nad Disallow direktivom ako je njena dužina karaktera duža.
Primer
User-agent: *
Allow: /about/company/
Disallow: /about/U primeru iznad, svi pretraživači, uključujući Google i Bing, nemaju dozvolu za pristup direktorijumu /about/, osim za pod-direktorijum /about/company/.
Primer
User-agent: *
Disallow: /about/
Allow: /about/company/
U ovom primeru, svi pretraživači osim Google-a i Bing-a nemaju dozvolu za pristup /about/ direktorijumu. To uključuje i direktorijum /about/company/.
Google-u i Bing-u je dozvoljen pristup, jer je Allow direktiva duža od Disallow direktive.
Samo jedna grupa direktiva po robotu
Možete definisati samo jednu grupu direktiva po pretraživaču. Imati više grupa direktiva za jednog pretraživača ih zbunjuje.
Budite što specifičniji
Disallow direktiva reaguje i na parcijalna podudaranja. Budite što specifičniji kada definišete Disallow direktivu kako biste sprečili nenamerno zabranjivanje pristupa fajlovima.
Primer:
User-agent: *
Disallow: /directory
Primer iznad ne dozvoljava pretraživačima pristup:
/directory
/directory/
/directory-name-1
/directory-name.html
/directory-name.php
/directory-name.pdfDirektive za sve pretraživače uz uključivanje direktiva za određeni pretraživač
Za jednog pretraživača važi samo jedna grupa direktiva. U slučaju kada se direktive namenjene svim pretraživačima kombinuju sa direktivama za određeni pretraživač, u obzir će biti uzete samo te specifične direktive. Da bi se specifični pretraživač pridržavao i direktiva namenjenih svim pretraživačima, te direktive trebate ponoviti za taj specifični pretraživač.
Pogledajmo primer koji će ovo razjasniti:
Primer:
User-agent: *
Disallow: /secret/
Disallow: /test/
Disallow: /not-launched-yet/User-agent: googlebot
Disallow: /not-launched-yet/U primeru iznad, svi pretraživači osim Google-a nemaju dozvolu za pristup /secret/, /test/ i /not-launched-yet/. Samo Google-u nije dozvoljen pristup /not-launched-yet/, ali mu je dozvoljen pristup /secret/ i /test/.
Ako ne želite da googlebot pristupi /secret/ i /not-launched-yet/ onda morate ponoviti te direktive za googlebot specifično:
User-agent: *
Disallow: /secret/
Disallow: /test/
Disallow: /not-launched-yet/User-agent: googlebot
Disallow: /secret/
Disallow: /not-launched-yet/Molimo vas da imate na umu da je vaš robots.txt fajl javno dostupan. Zabranjivanje sekcija veb sajta u njemu može biti iskorišćeno kao vektor napada od strane osoba sa zlonamernim namerama.
Sukobljene smernice: robots.txt vs. Google Search Console
Ukoliko vaš robots.txt fajl sukobljava sa podešavanjima definisanim u Google Search Console-u, Google često bira da koristi podešavanja definisana u Google Search Console-u umesto direktiva definisanih u robots.txt fajlu.
Pratite vaš robots.txt fajl
Važno je da pratite promene u vašem robots.txt fajlu. U ContentKing-u, primetili smo mnoge probleme gde netačne direktive i nagla promena u robots.txt fajlu izazivaju značajne SEO probleme.
Ovo posebno važi prilikom lansiranja novih funkcionalnosti ili novog veb sajta koji je bio pripremljen na testnoj okolini, jer ovi fajlovi često sadrže sledeći robots.txt sadržaj:
User-agent: *
Disallow: /Dozvolite svim robotima pristup svemu
Postoje različiti načini da kažete pretraživačima da imaju pristup svim fajlovima:
User-agent: *
Disallow:Ili imati prazan robots.txt fajl ili uopšte nemati robots.txt.
Zabranite svim robotima pristup svemu
Primer robots.txt fajla ispod zabranjuje svim pretraživačima pristup celom sajtu:
User-agent: *
Disallow: /Molimo obratite pažnju da samo JEDNO dodatno slovo može napraviti veliku razliku.
Svi Google botovi nemaju pristup
User-agent: googlebot
Disallow: /Molimo obratite pažnju da kada zabranjujete Googlebot-u, to važi za sve Google botove. To uključuje Google robote koji traže vesti (googlebot-news) i slike (googlebot-images).
Svi Google botovi, osim Googlebot news, nemaju pristup
User-agent: googlebot
Disallow: /User-agent: googlebot-news
Disallow:Googlebot i Slurp nemaju pristup
User-agent: Slurp
User-agent: googlebot
Disallow: /Svi roboti nemaju pristup dve direktorijumu
User-agent: *
Disallow: /admin/
Disallow: /private/Svi roboti nemaju pristup jednom specifičnom fajlu
User-agent: *
Disallow: /directory/some-pdf.pdfGooglebot nema pristup /admin/ a Slurp nema pristup /private/
User-agent: googlebot
Disallow: /admin/
User-agent: Slurp
Disallow: /private/Robots.txt fajl za WordPress
Sledeći robots.txt fajl je posebno optimizovan za WordPress, pretpostavljajući:
Ne želite da se pretraživači kreću po vašem administratorskom odeljku.
Ne želite da se pretraživači kreću po internim stranicama rezultata pretrage.
Ne želite da se pretraživači kreću po stranicama oznaka i autora.
Ne želite da se pretraživači kreću po vašoj 404 stranici.
User-agent: *
Disallow: /wp-admin/ #blokira pristup administratorskom odeljku
Disallow: /wp-login.php #blokira pristup administratorskom odeljku
Disallow: /search/ #blokira pristup internim stranicama rezultata pretrage
Disallow: ?s= #blokira pristup internim stranicama rezultata pretrage
Disallow: ?p= #blokira pristup stranicama za koje linkovi ne funkcionišu
Disallow: &p= #blokira pristup stranicama za koje linkovi ne funkcionišu
Disallow: &preview= #blokira pristup stranicama u prikazu pregleda
Disallow: /tag/ #blokira pristup stranicama oznaka
Disallow: /author/ #blokira pristup stranicama autora
Disallow: /404-error/ #blokira pristup 404 stranici
Sitemap: https://www.example.com/sitemap_index.xmlMolimo vas da imate na umu da će ovaj robots.txt fajl u većini slučajeva funkcionisati, ali uvek ga prilagodite i testirajte kako biste bili sigurni da odgovara vašoj tačnoj situaciji.



